From Experimentation to Implementation: Building a Successful MLops Framework for Scalable Machine Learning
Introduction to MLops
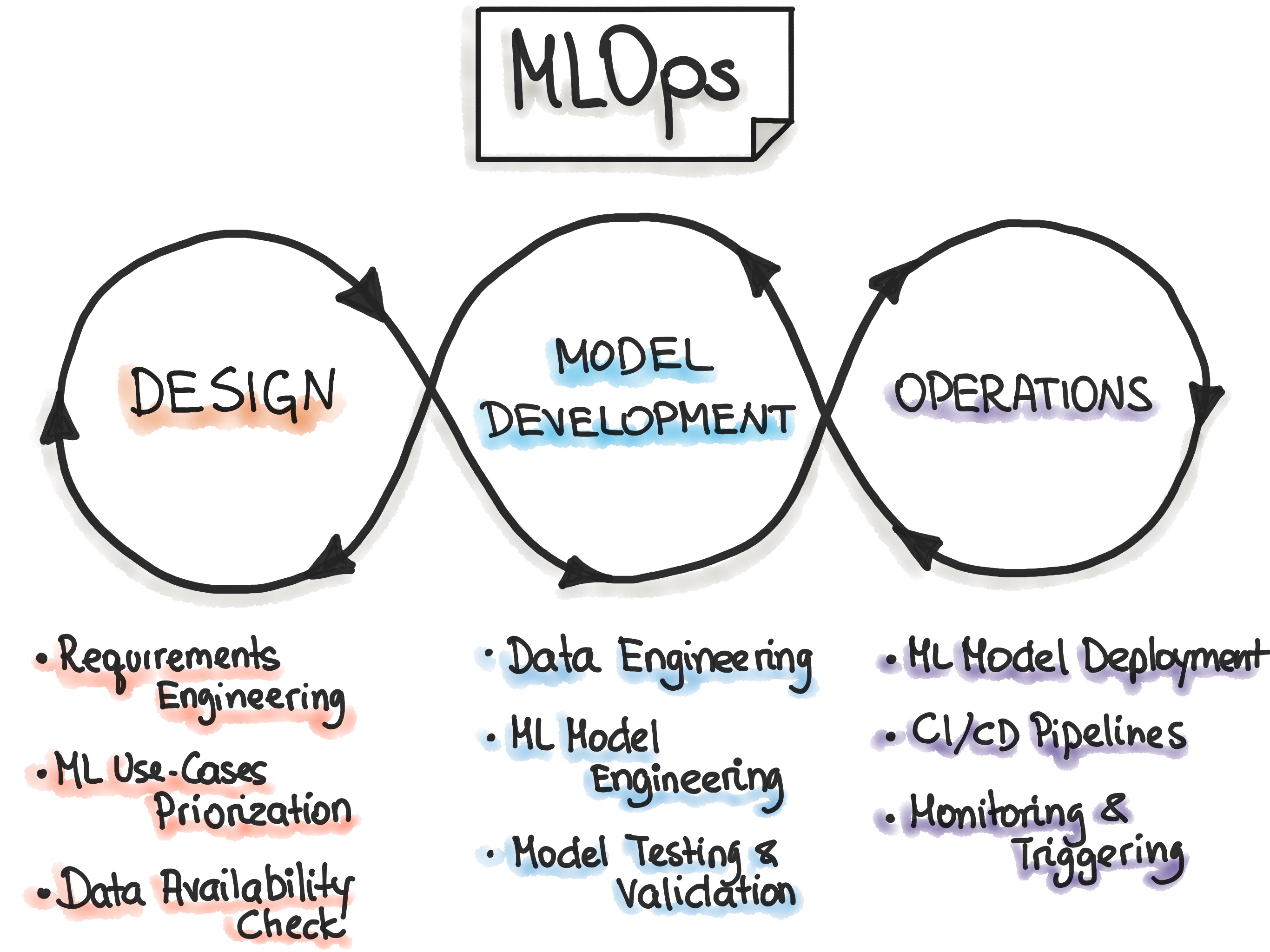 |
| Source: ml-ops.org |
What is MLops and Why is it Important?
 |
| Source: zenml.io |
MLops refers to the practices, processes, and tools used to streamline and automate the deployment, monitoring, and management of machine learning models in production environments. It combines the principles of software engineering, data engineering, and operations to ensure the smooth integration and operation of machine learning systems.
The importance of MLops lies in its ability to bridge the gap between data science experimentation and the implementation of machine learning models in real-world scenarios. Without a robust MLops framework, organizations often struggle to deploy models at scale, leading to wasted time, effort, and resources. MLops enables seamless collaboration between data scientists, engineers, and IT operations teams, ensuring that machine learning models are deployed reliably, monitored effectively, and updated efficiently throughout their lifecycle.
Benefits of Implementing MLops Framework
 |
| Source: geniusee.com |
Implementing a well-designed MLops framework offers numerous benefits for organizations looking to leverage machine learning effectively. Firstly, it enables faster model deployment, allowing organizations to rapidly derive insights from their data and make informed decisions. By automating the deployment process, MLops reduces manual errors and accelerates the time-to-market for machine learning applications.
Secondly, MLops ensures the reproducibility and scalability of machine learning models. By encapsulating the entire machine learning pipeline, including data preprocessing, feature engineering, model training, and deployment, organizations can easily reproduce and scale their models across different datasets and environments. This scalability enables organizations to handle increasing volumes of data without compromising the performance or reliability of their models.
Lastly, MLops enhances model monitoring and maintenance. By implementing robust monitoring and logging mechanisms, organizations can continuously monitor the performance of their models, detect anomalies, and trigger automated actions when necessary. This proactive approach to model maintenance helps prevent costly errors and ensures that machine learning models remain accurate and up-to-date in dynamic environments.
MLops in Practice: Case Studies and Success Stories
To truly understand the impact of MLops, let's delve into some real-world case studies and success stories that highlight the benefits of implementing an MLops framework.
Case Study 1: Company X - Streamlining Model Deployment
Company X, a leading e-commerce platform, struggled with deploying machine learning models in their production environment. The lack of a standardized MLops framework resulted in delays and inconsistencies in model deployment, leading to missed opportunities for personalized recommendations and targeted marketing campaigns.
To address this challenge, Company X implemented an MLops framework that automated the deployment process, ensuring seamless integration of machine learning models into their production pipeline. By leveraging MLops tools and platforms such as AWS and Sagemaker, they were able to deploy models faster, resulting in improved customer experience and increased revenue.
Case Study 2: Company Y - Scalable Model Training
Company Y, a healthcare organization, faced the challenge of training machine learning models on large-scale datasets while maintaining high performance and accuracy. Their existing infrastructure was unable to handle the increasing data volumes, resulting in prolonged training times and compromised model performance.
To overcome this hurdle, Company Y adopted MLops practices, leveraging Databricks as their MLops platform. By implementing distributed computing and parallel processing techniques, they were able to train models on massive datasets in a fraction of the time. This scalability allowed them to process and analyze healthcare data more efficiently, leading to improved patient outcomes and faster diagnosis.
These case studies demonstrate the tangible benefits of implementing an MLops framework, ranging from improved deployment efficiency to enhanced scalability and performance.
Key Components of a Successful MLops Framework
Building a successful MLops framework requires a holistic approach, encompassing various components and considerations. Let's explore the key components that form the foundation of an effective MLops framework.
1. Data Management and Versioning
Data is at the core of machine learning models, and effective data management is crucial for MLops. Organizations need to establish robust data pipelines, ensuring data quality, integrity, and accessibility. Data versioning mechanisms also play a vital role in tracking changes and enabling reproducibility of models.
2. Model Deployment and Orchestration
Efficient model deployment and orchestration are essential for MLops. Organizations should leverage tools and platforms like AWS, Sagemaker, and Databricks to automate the deployment process, manage model versions, and ensure seamless integration with existing systems.
3. Monitoring and Alerting
Continuous monitoring and alerting mechanisms are critical for maintaining model performance and reliability. MLops frameworks should include monitoring tools that track model performance metrics, detect anomalies, and trigger alerts when performance deviates from the expected standards.
4. Model Versioning and Rollbacks
Model versioning and rollbacks enable organizations to manage and track changes made to machine learning models. This ensures reproducibility, facilitates collaboration, and helps maintain a reliable model repository.
5. Collaboration and Governance
MLops frameworks should promote collaboration and governance across data science, engineering, and operations teams. Establishing clear roles, responsibilities, and workflows encourages effective collaboration and ensures compliance with regulatory requirements.
MLops Tools and Platforms - AWS, Sagemaker, Databricks
Implementing MLops effectively requires leveraging the right tools and platforms. Let's explore three popular MLops tools and platforms - AWS, Sagemaker, and Databricks - and their key features.
1. AWS
AWS provides a comprehensive suite of services that facilitate the implementation of MLops frameworks. With services like AWS Lambda, AWS Step Functions, and AWS CodePipeline, organizations can automate the entire machine learning pipeline, from data preprocessing to model deployment and monitoring.
2. Sagemaker
 |
| Source: AWS Cloud |
Sagemaker, an Amazon service, offers a managed platform for building, training, and deploying machine learning models at scale. It provides pre-configured environments, notebooks, and libraries that streamline the machine learning workflow, making it easier to implement MLops practices.
3. Databricks
 |
| Source: Databricks |
Databricks is a unified analytics platform that combines data engineering, data science, and MLops capabilities. It enables organizations to build and deploy machine learning models using collaborative notebooks, while also providing robust data processing and analysis capabilities.
By leveraging these MLops tools and platforms, organizations can accelerate the implementation of MLops frameworks and achieve scalable machine learning operations.
Implementing MLops on AWS
AWS offers a wide range of services that facilitate the implementation of MLops frameworks. Let's explore the steps involved in implementing MLops on AWS.
1. Data Preparation and Versioning
The first step in implementing MLops on AWS is to establish a robust data management system. This involves setting up data pipelines, ensuring data quality, and implementing data versioning mechanisms using services like AWS Glue, AWS Data Pipeline, and AWS CodeCommit.
2. Model Training and Deployment
Once the data management system is in place, organizations can leverage AWS Sagemaker to train and deploy machine learning models. Sagemaker provides a managed environment for building and training models, as well as a deployment pipeline that integrates with AWS CodePipeline for seamless model deployment.
3. Monitoring and Alerting
To ensure the performance and reliability of deployed models, organizations should implement monitoring and alerting mechanisms using services like AWS CloudWatch and AWS Lambda. These services enable real-time monitoring of model metrics and trigger alerts when anomalies are detected.
4. Continuous Integration and Continuous Deployment (CI/CD)
To automate the MLops workflow, organizations can leverage AWS CodePipeline and AWS CodeCommit for continuous integration and continuous deployment. This ensures that changes to the model code and configurations are automatically tested, deployed, and monitored.
By following these steps and leveraging the MLops capabilities of AWS, organizations can build a scalable and efficient machine learning infrastructure.
Implementing MLops on Sagemaker
AWS Sagemaker provides a managed platform for building, training, and deploying machine learning models. Let's explore the steps involved in implementing MLops on Sagemaker.
1. Model Development and Experimentation
The first step in implementing MLops on Sagemaker is to develop and experiment with machine learning models using Sagemaker notebooks. Sagemaker notebooks provide a collaborative environment for data scientists to develop and test models using popular frameworks like TensorFlow and PyTorch.
2. Model Training and Hyperparameter Tuning
Once the initial model development is complete, organizations can leverage Sagemaker's built-in training capabilities to train the models at scale. Sagemaker provides distributed training options and automatic hyperparameter tuning, allowing organizations to optimize their models for performance and accuracy.
3. Model Deployment and Monitoring
After training the models, organizations can deploy them using Sagemaker's managed hosting options. Sagemaker provides secure and scalable endpoints for deploying models, which can be easily integrated with existing applications. Additionally, Sagemaker offers built-in monitoring capabilities that enable organizations to track model performance and detect anomalies.
4. Model Versioning and Rollbacks
To manage changes and track model versions, organizations can leverage Sagemaker's model versioning and rollbacks features. These features enable organizations to easily revert to previous versions of the model, ensuring reproducibility and facilitating collaboration.
By following these steps and utilizing the MLops capabilities of Sagemaker, organizations can streamline their machine learning workflows and achieve efficient and scalable model deployment.
Implementing MLops on Databricks
Databricks is a unified analytics platform that combines data engineering, data science, and MLops capabilities. Let's explore the steps involved in implementing MLops on Databricks.
1. Data Preprocessing and Analysis
The first step in implementing MLops on Databricks is to preprocess and analyze the data using Databricks notebooks. Databricks notebooks provide a collaborative environment for data scientists and engineers to explore, transform, and analyze data using popular languages like Python and Scala.
2. Model Development and Training
Once the data preprocessing and analysis are complete, organizations can leverage Databricks to develop and train machine learning models. Databricks provides a seamless integration with popular machine learning libraries like TensorFlow, PyTorch, and scikit-learn, enabling organizations to build and train models at scale.
3. Model Deployment and Monitoring
After training the models, organizations can deploy them using Databricks' MLflow integration. MLflow provides a platform-agnostic framework for managing the deployment and monitoring of machine learning models. It allows organizations to track model versions, deploy models as REST APIs, and monitor model performance using custom metrics.
4. Collaboration and Governance
To ensure effective collaboration and governance, organizations can leverage Databricks' collaborative features and role-based access control (RBAC) mechanisms. Databricks notebooks enable data scientists and engineers to collaborate on model development, while RBAC ensures that access to sensitive data and models is restricted to authorized personnel.
By following these steps and utilizing the MLops capabilities of Databricks, organizations can establish a robust and scalable machine learning infrastructure.
Best Practices and Tips for Building a Scalable MLops Framework
Building a scalable MLops framework requires careful planning and adherence to best practices. Here are some tips to help organizations build a successful and scalable MLops framework:
- Establish cross-functional collaboration: Encourage collaboration between data science, engineering, and operations teams to ensure a holistic approach to MLops.
- Automate the ML pipeline: Leverage automation tools and platforms like AWS, Sagemaker, and Databricks to automate the entire machine learning pipeline, from data preprocessing to model deployment and monitoring.
- Implement version control: Use version control systems like Git and services like AWS CodeCommit to track changes to code, configurations, and data, enabling reproducibility and facilitating collaboration.
- Ensure robust monitoring and alerting: Implement monitoring and alerting mechanisms to continuously track model performance, detect anomalies, and trigger alerts when necessary.
- Regularly update and retrain models: Keep models up-to-date by regularly updating them with new data and retraining them using the latest techniques and algorithms.
- Establish clear documentation and communication: Document all aspects of the MLops framework, including data pipelines, model architectures, and deployment processes. Ensure effective communication among team members to avoid misunderstandings and facilitate knowledge sharing.
By following these best practices and tips, organizations can build a scalable MLops framework that enables efficient machine learning operations.
Challenges and Solutions in Implementing MLops
While MLops offers numerous benefits, organizations often face challenges when implementing MLops frameworks. Let's explore some common challenges and their solutions:
Challenge 1: Data Management and Integration
Managing and integrating data from various sources can be challenging. Organizations must establish robust data pipelines, ensure data quality, and implement data versioning mechanisms. By leveraging tools like AWS Glue, Apache Kafka, and Apache Airflow, organizations can streamline data management and integration.
Challenge 2: Model Deployment and Versioning
Deploying and versioning models can be complex, especially in dynamic environments. Organizations should leverage MLops platforms like AWS Sagemaker and Databricks MLflow to automate model deployment, manage model versions, and ensure seamless integration with existing systems.
Challenge 3: Model Monitoring and Maintenance
Monitoring and maintaining models in production environments can be challenging. Organizations should implement monitoring and alerting mechanisms using tools like AWS CloudWatch and Databricks MLflow. Regular model retraining and updating also help ensure model accuracy and reliability.
Challenge 4: Collaboration and Governance
Effective collaboration and governance across teams can be a challenge, especially in large organizations. Establishing clear roles, responsibilities, and workflows, and leveraging collaborative platforms like Databricks notebooks, helps promote effective collaboration and ensures compliance with regulatory requirements.
By addressing these challenges and implementing the corresponding solutions, organizations can overcome the obstacles associated with implementing MLops frameworks and achieve successful and scalable machine learning operations.
Conclusion
Building a successful MLops framework is essential for organizations looking to leverage machine learning effectively. MLops enables faster model deployment, ensures reproducibility and scalability, and enhances model monitoring and maintenance. By implementing MLops on platforms like AWS, Sagemaker, and Databricks, organizations can streamline their machine learning workflows and achieve efficient and scalable machine learning operations.



Comments
Post a Comment